
Step-by-Step Guide to Extracting PDF Pages with Python
Category: Python
Date: January 2024
Views: 992
Have you ever needed to extract specific pages or a single page from a PDF document? Whether you're dealing with lengthy reports, research papers, or manuals, extracting only the pages you need can save time and streamline your workflow. In this article, we'll introduce a Python script that allows you to precisely extract pages from a PDF file, along with a convenient shell script to simplify its usage.
If you're ready to extract specific pages or a single page from a PDF document, let's get started! Before diving into the Python script, ensure you have the necessary dependencies installed. First, you'll need to have the PyPDF2 package installed. If you haven't already installed it, you can do so using pip:
pip install PyPDF2
Additionally, if you prefer to keep your Python environments isolated, consider setting up a local virtual environment. This allows you to manage package dependencies for individual projects without affecting the system-wide Python installation. Here's how you can create and activate a virtual environment:
# Create a virtual environment named 'venv'
python -m venv venv
# Activate the virtual environment
source venv/bin/activate (on Unix/Linux)
venv\Scripts\activate.bat (on Windows)
Once you've prepared your environment, you're ready to dive into the Python script for extracting pages from PDF documents. Let's explore how to use the script effectively!
Understanding the Python Script: pdf_extract.py
The core of our solution is a Python script named pdf_extract.py. This script leverages the PyPDF2 library, a powerful tool for working with PDF files in Python.
#!/usr/bin/python
from PyPDF2 import PdfReader, PdfWriter
import sys
import os
# Get the command-line arguments
args = sys.argv[1:]
num_args = len(args)
# Check the number of arguments and set the input file, start page, and end page accordingly
if num_args == 2:
input_file = args[0]
start_page = int(args[1])
end_page = start_page
elif num_args == 3:
input_file = args[0]
start_page = int(args[1])
end_page = int(args[2])
else:
print("Usage: python extract_pages.py input_file start_page [end_page]")
sys.exit()
print("start page",start_page)
print("end page",end_page)
pdf = PdfReader(input_file)
pdf_writer = PdfWriter()
fn, ext = os.path.splitext(input_file)
output_file = f"{fn}-pages-{start_page}-{end_page}{ext}"
print(f"file contains {len(pdf.pages)} pages")
if end_page == len(pdf.pages):
end_page = end_page -1
for page in range(start_page,end_page+1):
current_page = pdf.pages[page]
pdf_writer.add_page(current_page)
with open(output_file, "wb") as out:
pdf_writer.write(out)
print("created", output_file)
Here's how the script works:
Command-line Arguments: The script accepts command-line arguments to specify the input PDF file, the starting page, and optionally, the ending page.
Page Extraction: It opens the input PDF file and extracts the specified pages into a new PDF file.
Let's break down how to use the script:
Usage:
python pdf_extract.py input_file start_page [end_page]
input_file: Path to the input PDF file.
start_page: Page number from which extraction should begin.
end_page (optional): Page number at which extraction should end. If not provided, extraction will only include the specified start_page.
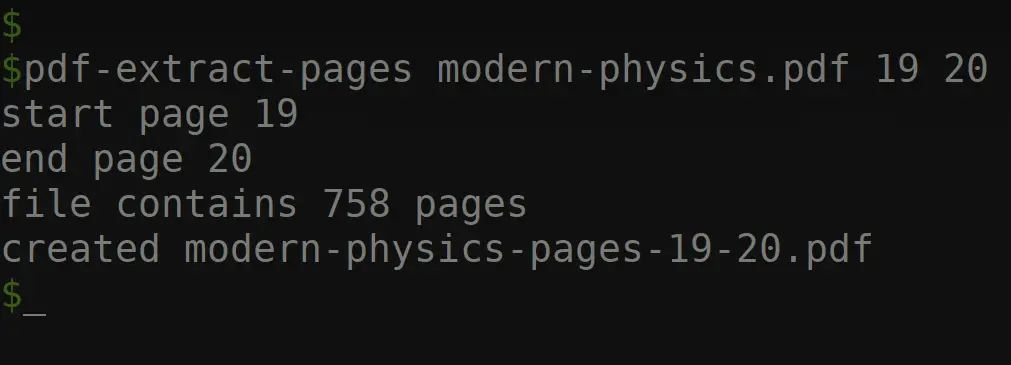
Shell Script for Simplified Usage
To make the extraction process even more convenient, we've created a shell script that wraps the Python script. This shell script takes care of activating a Python virtual environment (if you're using one) and calling the Python script with the provided arguments.
Here's the shell script named pdf_extract.sh:
#!/bin/bash
source "${HOME}/bin/venv/bin/activate" # Activate Python virtual environment (if applicable)
python "${HOME}/bin/pdf_extract.py" "$1" $2 $3 # Call the Python script with arguments
Usage:
./pdf_extract.sh input_file start_page [end_page]
input_file: Path to the input PDF file.
start_page: Page number from which extraction should begin.
end_page (optional): Page number at which extraction should end. If not provided, extraction will only include the specified start_page.
Enhancing Your Workflow
By using the pdf_extract.py Python script and the pdf_extract.sh shell script, you can efficiently extract specific pages or a single page from PDF documents. Whether you're managing academic papers, business documents, or personal files, this tool can help you extract the content you need, simplifying your workflow and saving you time.
With these tools and tips at your disposal, managing PDF documents will become a breeze. We welcome your feedback! If you have any suggestions or improvements for the script, feel free to share them with us. in a comment
Related Articles







Most Recent Articles




Most Viewed Articles






0 Comments, latest